Nieuws: Hoe je een bestseller kunt voorspellen op basis van de woordkeuze van de schrijver
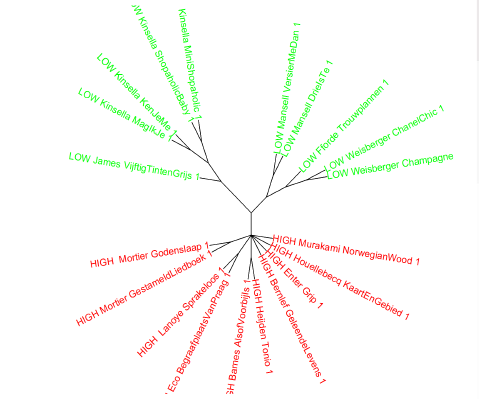
Op de website van Het Letterenfonds staat een column van Karina van Dalen-Oskam over het big data-onderzoek waar Patrick Swart van WPG zo blij over is. Van Dalen-Oskam is onderzoeker bij het Huygens Instituut en gaf onlangs een lezing voor het Letterenfonds. Het is een voortzetting van het grote Nationale Lezersonderzoek van enkele jaren geleden waarbij lezers een inschatting moesten geven van de literaire kwaliteit van een werk. Dit waren toen de resultaten.
Top 10 meest literair
1 Alsof het voorbij is, Julian Barnes
2 Godenslaap, Erwin Mortier
3 Gestameld liedboek, Erwin Mortier
4 De kaart en het gebied, Michel Houellebecq
5 Sprakeloos, Tom Lanoye
6 Norwegian Wood, Haruki Murakami
7 Tonio, A.F.Th. van der Heijden
8 Grip, Stephan Enter
9 Geleende levens, J. Bernlef
10 Begraafplaats van Praag, Umberto Eco
Top 10 minst literair
1 Vijftig tinten grijs, E.L. James
2 Shopaholic & Baby, Sophie Kinsella
3 Mag ik je nummer even?, Sophie Kinsella
4 Chanel Chic, Lauren Weisberger
5 Mini Shopaholic, Sophie Kinsella
6 Ken je me nog?, Sophie Kinsella
7 Versier me dan, Jill Mansell
8 Champagne in Chateau Marmont, Lauren Weisberger
9 Trouwplannen, Katie Fforde
10 Drie is te veel, Jill Mansell
In het vervolgonderzoek is gekeken naar woordkeus in romans van De Bezige Bij en Bruna. Deze uitgeverijen onder de paraplu van WPG gaven daarbij ook aan in hoeverre de onderzochte romans goed waren verkocht.
Aan een neuraal netwerk boden we de tekst van 200 romans aan. Meer precies: het algoritme mat in gedeelten van gelijke omvang (samples) uit de romans hoe vaak welke woorden werden gebruikt. Van elk sample gaven we ook aan of het uit een bestseller of een slecht verkocht boek kwam. Het neurale netwerk wordt op die manier met de samples getraind om op basis van het woordgebruik bestsellers te onderscheiden van boeken die nauwelijks werden verkocht.
Op grond van patronen die werden gevonden kon men kijken of de computer kon voorspellen of 60 romans die nog niet waren onderzocht bestsellers waren of niet. In 78% deed de computer een juiste voorspelling.
Van Dalen-Oskam onderzoekt verder ‘naar patronen van woordgebruik, betekenissen, en verhaalstructuren die kenmerkend zijn voor slecht verkochte titels en bestsellers. We hopen daarmee bovendien meer kennis op te doen over wat onderscheidend is voor kwaliteit in literaire context.’







